20.4月1日 项目:学生成绩分析—图表绘制
概述:
从数据库中读取成绩数据,并按照班级绘制成绩分布图
目标图:
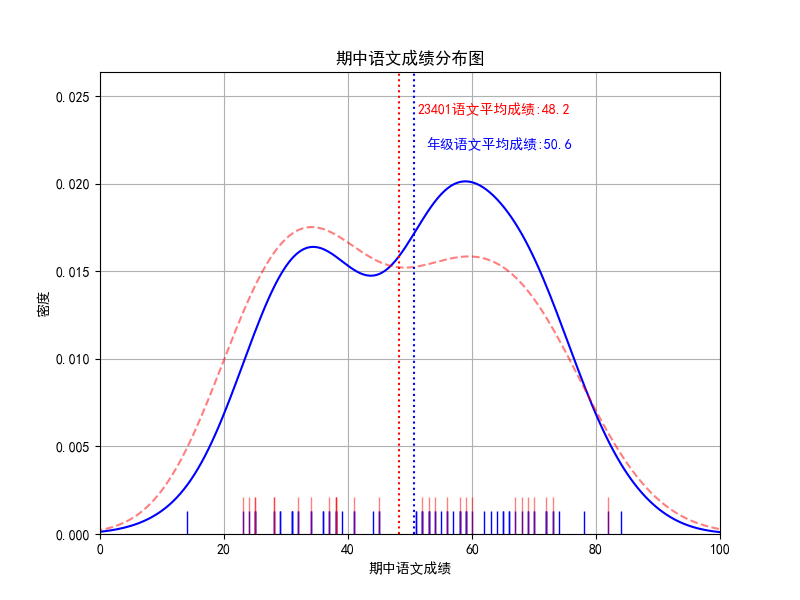
1. 准备工作:
还原mysql数据库,为了同意进度。本次数据库,进行统一还原操作
方式可以通过:
cj.sql
-
phpadmin
-
通过命令导入(本次使用)
通过以下命令将cj.sql传输进ubuntu
scp .\cj.sql xiandai@192.168.120.129:/home/xiandai
随后进入mysql 导入数据库
mysql> create database scores;
Query OK, 1 row affected (0.34 sec)
mysql> use scores;
Database changed
mysql> source /home/xiandai/cj.sql
记得通过 select * from student_scores;
查看导入效果。
2. python获取mysql数据
目标获取数据并转为dataframe形式
导入库(之前学习)
下载库:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xxxxxxx
# 数据分析三剑客
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
# 处理mysql
import pymysql
数据处理函数(之前学习)
def get_database_connection():
connection = pymysql.connect(host='192.168.40.105',
user='xd',
password='123',
db='scores',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
return connection, connection.cursor()
获取数据函数(新)
def get_student_scores():
"""从数据库中获取学生成绩数据并将其转换为 pandas DataFrame。
Args:
None
Returns:
pandas.DataFrame: 包含学生成绩数据的 DataFrame。
"""
conn, cursor = get_database_connection()
try:
cursor.execute("select * from student_scores;")
# 一次性获取所有结果
data = cursor.fetchall()
# 将数据转换为 DataFrame
df = pd.DataFrame(data)
return df
finally:
conn.close() # 关闭连接
此部分代码(不完整,略写)
import numpy as np
#......
def get_database_connection():
#....
def get_student_scores():
#....
df = get_student_scores()
print(df)
现在我们已经将学生成绩数据存放入了df变量。
3. 数据清洗
获取到df中部分数据存在问题,例如缺考数据使用-4表示的
将缺考数据剔除
修改get_student_scores
def get_student_scores():
"""从数据库中获取学生成绩数据并将其转换为 pandas DataFrame。
Args:
None
Returns:
pandas.DataFrame: 包含学生成绩数据的 DataFrame。
"""
conn, cursor = get_database_connection()
try:
cursor.execute("select * from student_scores;")
# 一次性获取所有结果
data = cursor.fetchall()
# 将数据转换为 DataFrame
df = pd.DataFrame(data)
# 将"-4"替换为NaN
df.replace(-4, np.nan, inplace=True)
df.dropna(inplace=True)
return df
finally:
conn.close() # 关闭连接
4.分析23401班期中语文情况
df中包含23401、23402、23403班的期中期末语数英数据
从df中过滤出需要的数据(23401班,期中语文)
获取期中语文数据
mid_chinese=df[['class','name','mid_term_chinese']]
print(mid_chinese)
在此基础上获取 23401班期中语文数据
mid_chinese_23401=mid_chinese[mid_chinese['class']=='23401']
print(mid_chinese_23401)
5. 绘制年级期中语文成绩分布图
先套用模板格式
plt.rcParams['font.sans-serif']=['SimHei']
plt.figure(figsize=(8, 6))
plt.xlabel('期中语文成绩')
plt.ylabel('密度')
plt.title('期中语文成绩分布图')
plt.xlim(0,100)
#在这里添加绘制的曲线
plt.grid(True)
plt.show()
核密度估计(kde)
这里用到一种统计方式:核密度估计(kde)
核密度估计(Kernel Density Estimation,简称KDE)是一种非参数统计方法,用于估计数据集的概率密度函数
在数据可视化中,核密度估计曲线经常用于替代直方图来展示数据的分布情况,特别是当数据集比较小或连续性较强时。核密度估计曲线能够更平滑地展现数据的分布情况,同时保留了数据集的原始信息。
引入seaborn
Seaborn 是 Python 中一个用于数据可视化的库,它基于 matplotlib 库构建,并提供了一套高级 API,可以更轻松、更方便地创建具有吸引力和信息量的统计图形。
Seaborn 的主要功能包括:
- 提供了一系列预定义的主题和样式,可以快速创建美观且一致的图表。
import seaborn as sns
绘制核密度估计曲线
核心语句
sns.kdeplot(
data=mid_chinese, # 这是要绘制的数据集
x="mid_term_chinese", # 指定了在数据集中表示期中语文成绩的列
color="blue",
label="语文期中考试成绩" # 设置图例标签
)
-
详细版本(只做参考,不需要使用)
sns.kdeplot( data=mid_chinese, x="mid_term_chinese", color="lightseagreen", # 颜色 linewidth=1.5, # 线宽 linestyle="--", # 虚线 alpha=0.5, # 降低曲线的透明度 label="语文期中考试成绩" # 设置图例标签 )
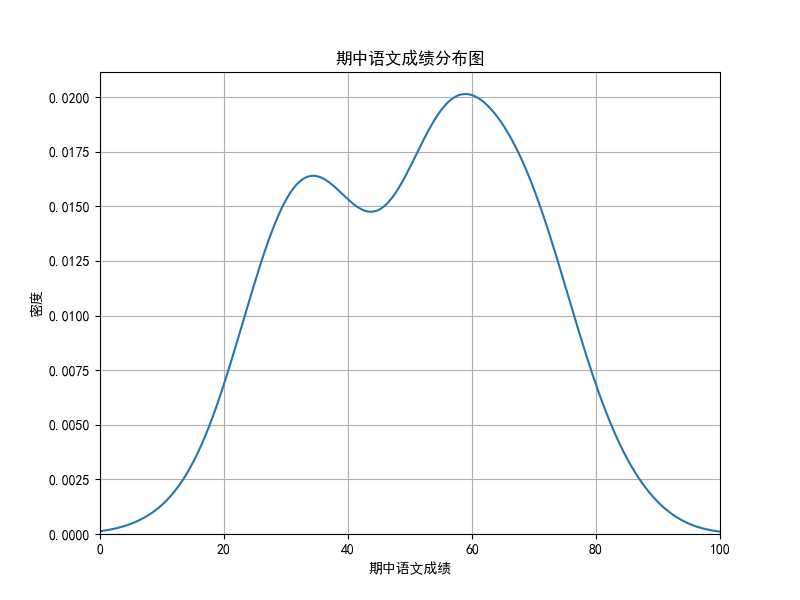
绘制实际数据分布情况
rugplot 绘制出一维数组中数据点实际的分布位置情况,单纯的将记录值在坐标轴上表现出来,其可以展示原始的数据离散分布情况
sns.rugplot(
data=mid_chinese,
x="mid_term_chinese",
height=0.05, # 控制 rug plot 的高度
color="blue",
)
完整代码
plt.rcParams['font.sans-serif']=['SimHei']
plt.figure(figsize=(8, 6))
plt.xlabel('期中语文成绩')
plt.ylabel('密度')
plt.title('期中语文成绩分布图')
plt.xlim(0,100)
# 绘制核密度估计曲线
sns.kdeplot(
data=mid_chinese,
x="mid_term_chinese",
label="语文期中考试成绩" # 设置图例标签
)
# 绘制实际数据分布
sns.rugplot(
data=mid_chinese,
x="mid_term_chinese",
height=0.05, # 控制 rug plot 的高度
color="blue",
)
plt.grid(True)
plt.show()
练习:绘制23401班和全年级成绩对比图
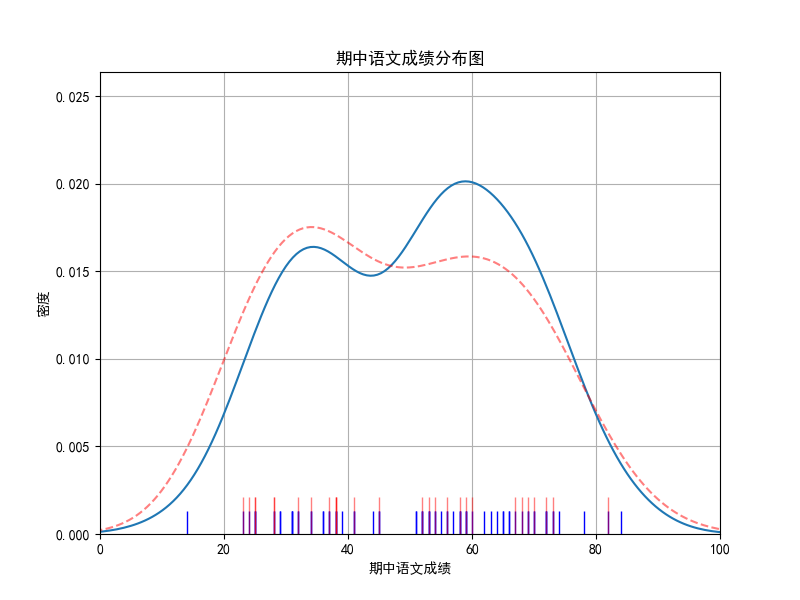
6. 绘制班级平均/年级平均成绩在图中位置
计算平均成绩
mid_chinese_mean=mid_chinese['mid_term_chinese'].mean()
mid_chinese_23401_mean=mid_chinese_23401['mid_term_chinese'].mean()
绘制辅助线
plt.axvline(mid_chinese_mean, color="blue",linestyle=":")
绘制文本
text_str='年级语文平均成绩:' +str(mid_chinese_mean)
plt.text(mid_chinese_mean+2,0.022, text_str,color="blue",)
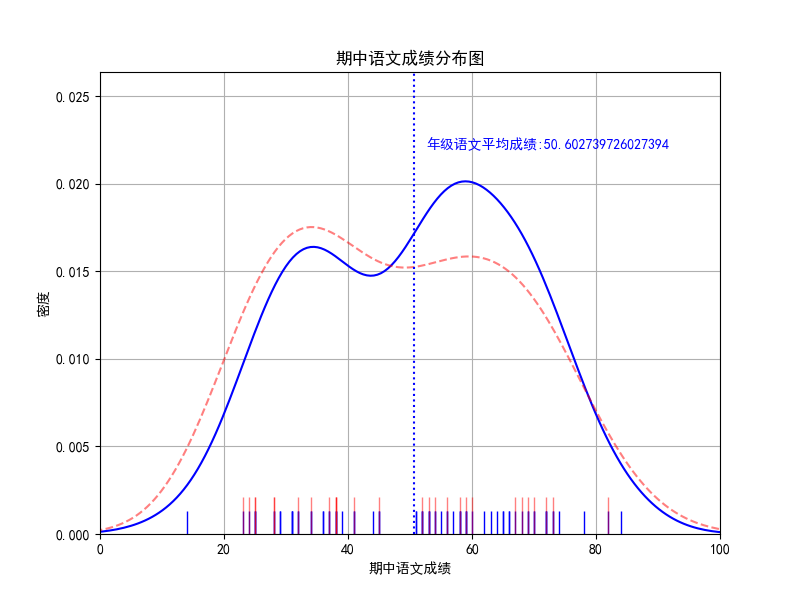
以上绘制效果并不好,小数太多了,需要格式化,修改后如下
plt.text(mid_chinese_mean+2,0.022, '年级语文平均成绩:%.1f' %(mid_chinese_mean),color="blue",)
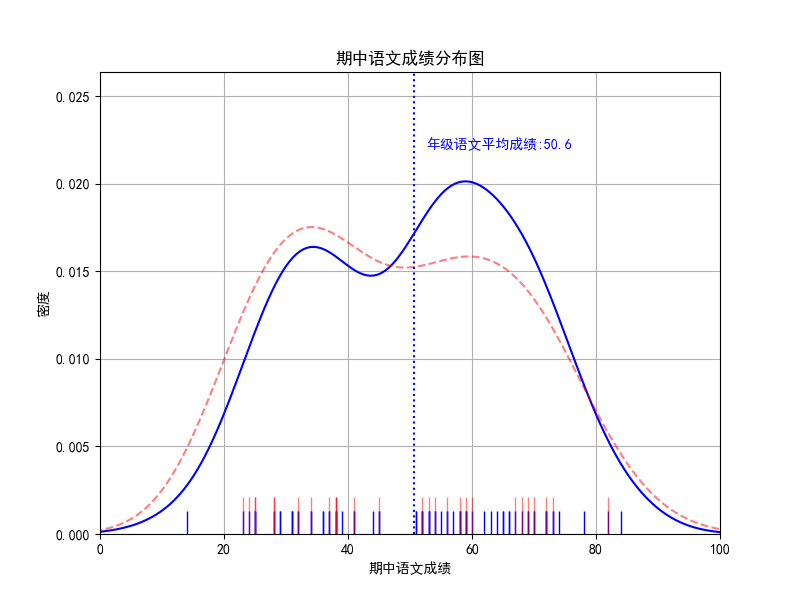
练习:加上23401班的辅助线
完整代码
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
import pymysql
import seaborn as sns
def get_database_connection():
connection = pymysql.connect(host='192.168.40.105',
user='xd',
password='123',
db='scores',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
return connection, connection.cursor()
def get_student_scores():
conn, cursor = get_database_connection()
try:
cursor.execute("select * from student_scores;")
# 一次性获取所有结果
data = cursor.fetchall()
# 将数据转换为 DataFrame
df = pd.DataFrame(data)
# 将"-4"替换为NaN
df.replace(-4, np.nan, inplace=True)
df.dropna(inplace=True)
return df
finally:
conn.close() # 关闭连接
df = get_student_scores()
mid_chinese=df[['class','name','mid_term_chinese']]
mid_chinese_23401=mid_chinese[mid_chinese['class']=='23401']
plt.rcParams['font.sans-serif']=['SimHei']
plt.figure(figsize=(8, 6))
plt.xlabel('期中语文成绩')
plt.ylabel('密度')
plt.title('期中语文成绩分布图')
plt.xlim(0,100)
# 绘制核密度估计曲线
sns.kdeplot(
data=mid_chinese,
x="mid_term_chinese",
label="语文期中考试成绩" ,
color="blue",
)
sns.kdeplot(
data=mid_chinese_23401,
x="mid_term_chinese",
label="23401班语文期中考试成绩" , # 设置图例标签
color='red',
linestyle="--", # 虚线
alpha=0.5,
)
# 绘制实际数据分布
sns.rugplot(
data=mid_chinese,
x="mid_term_chinese",
height=0.05, # 控制 rug plot 的高度
color="blue",
)
sns.rugplot(
data=mid_chinese_23401,
x="mid_term_chinese",
height=0.08, # 控制 rug plot 的高度
color="red",
alpha=0.5,
)
mid_chinese_mean=mid_chinese['mid_term_chinese'].mean()
mid_chinese_23401_mean=mid_chinese_23401['mid_term_chinese'].mean()
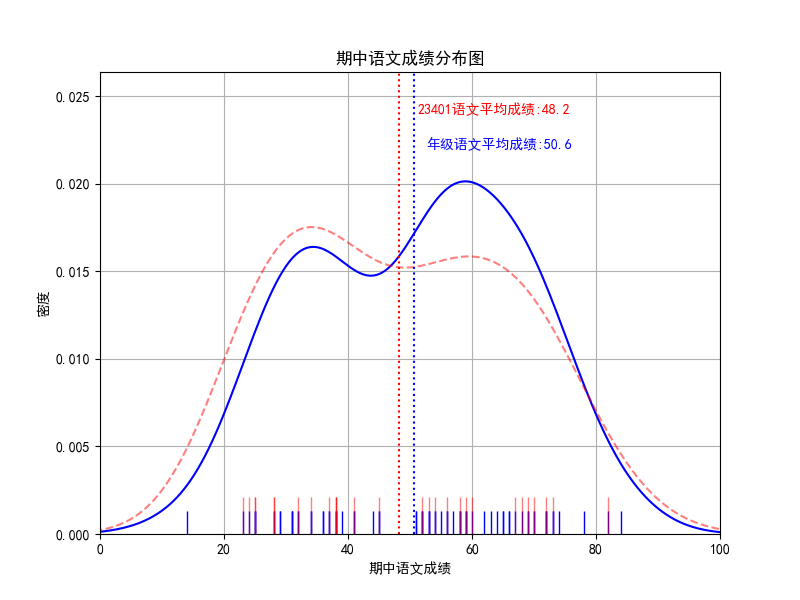
plt.axvline(mid_chinese_mean, color="blue",linestyle=":")
plt.text(mid_chinese_mean+2,0.022, '年级语文平均成绩:%.1f' %(mid_chinese_mean),color="blue",)
plt.axvline(mid_chinese_23401_mean, color="red",linestyle=":")
plt.text(mid_chinese_23401_mean+3,0.024, '23401语文平均成绩:%.1f' %(mid_chinese_23401_mean),color="red",)
plt.grid(True)
plt.show()
