14.3月18日 数据分析pandas—DataFrame
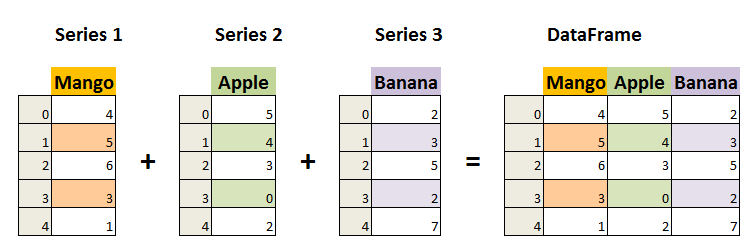
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
类似于excel表格了
DataFrame 特点:
- 列和行: DataFrame 由多个列组成,每一列都有一个名称,可以看作是一个 Series。同时,DataFrame 有一个行索引,用于标识每一行。
- 二维结构: DataFrame 是一个二维表格,具有行和列。可以将其视为多个 Series 对象组成的字典。
- 列的数据类型: 不同的列可以包含不同的数据类型,例如整数、浮点数、字符串等。
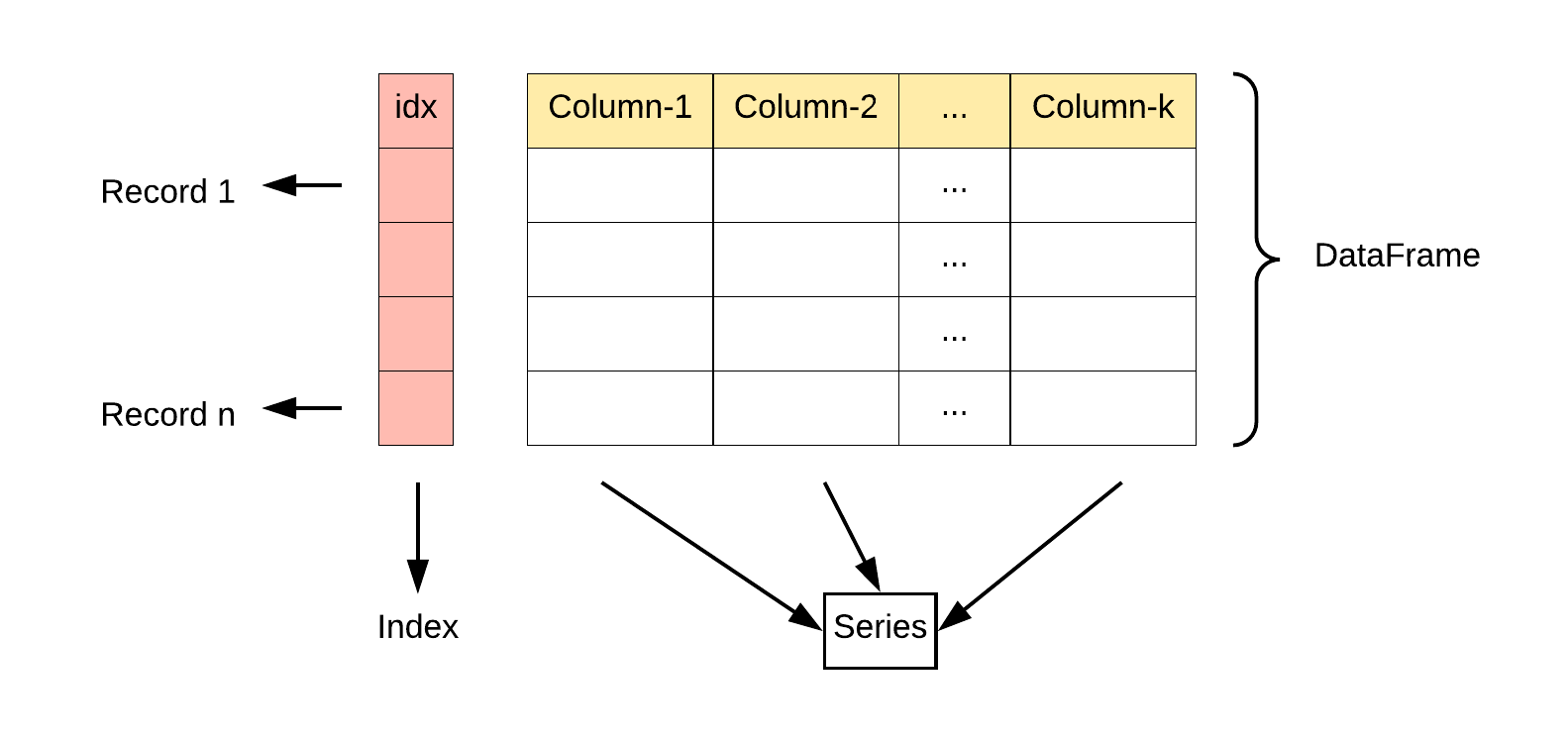
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签。
- columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
Pandas DataFrame 是一个二维的数组结构,类似二维数组。
DataFrame创建方式
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
使用列表创建
data = [['Google',10],['Runoob',12],['Wiki',13]]
df = pd.DataFrame(data=data,columns=['Site','Age'])
df
使用ndarrays创建(推荐)
data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13],'cost':[3,4,6]}
df = pd.DataFrame(data)
df
使用字典创建(不推荐)
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
df
::: info 注意
这其中出现了空值!
没有对应的部分数据为 NaN。
:::
DateFrame的取值方式
取单值返回Series
data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13],'cost':[3,4,6]}
df = pd.DataFrame(data)
df
Pandas 可以使用 loc 属性返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1,以此类推:
注意以下的区别!
data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13],'cost':[3,4,6]}
df = pd.DataFrame(data,index=['d1','d2','d3'])
print(df)
# print(df.loc[0]) 报错
# print(df.iloc[0]) 对
print(df.loc['d3'])
data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13],'cost':[3,4,6]}
df = pd.DataFrame(data)
print(df)
print(df.loc[0])
注意:以上的返回结果其实就是一个 Pandas Series 数据。
取多值返回DataFrame
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行和第二行
print(df.loc[[0, 1]])
注意:返回结果其实就是一个 Pandas DataFrame 数据。
DataFrame的操作方式
基本操作:
# 获取列
name_column = df['Name']# 注意这里没有loc 注意区分
# 获取行
first_row = df.iloc[0]
# 选择多列
subset = df[['Name', 'Age']]
# 过滤行
filtered_rows = df[df['Age'] > 30]
属性和方法:
# 获取列名
columns = df.columns
# 获取形状(行数和列数)
shape = df.shape
# 获取索引
index = df.index
# 获取描述统计信息
stats = df.describe()
数据操作:(可以用chat查参数含义)
# 添加新列
df['Salary'] = [50000, 60000, 70000]
# 删除列
df.drop('City', axis=1, inplace=True)
# 排序
df.sort_values(by='Age', ascending=False, inplace=True)
# 重命名列
df.rename(columns={'Name': 'Full Name'}, inplace=True)
从外部数据源创建 DataFrame:
# 从CSV文件创建 DataFrame
df_csv = pd.read_csv('example.csv')
# 从Excel文件创建 DataFrame
df_excel = pd.read_excel('example.xlsx')
项目: 工资分析
步骤一:数据导入
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
df_csv = pd.read_csv('./4. Pandas/工资数据.csv',encoding='utf-8')
print(df_csv)
步骤二: 取工号00027的“月份”、“实发工资”数据
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
df_csv = pd.read_csv('./第五周/工资数据.csv')
num_27=df_csv[df_csv['工号']==27]
print(num_27[['月份','实发金额']])
步骤三:取工号00027,整个2023年的“月份”、“实发工资”数据
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
df_csv = pd.read_csv('./第五周/工资数据.csv')
num_27=df_csv[df_csv['工号']==27]
num_27_2023=num_27[(num_27['月份']>="2023-01") & (num_27['月份']<"2024-01")]
print(num_27_2023[['月份','实发金额']])
步骤四:用折现图展示数据
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
df_csv = pd.read_csv('./第五周/工资数据.csv')
num_27=df_csv[df_csv['工号']==27]
num_27_2023=num_27[(num_27['月份']>="2023-01") & (num_27['月份']<"2024-01")]
plt.rcParams["font.family"]="SimHei"
fig=plt.figure(figsize=(6,4))
ax=fig.add_subplot()
ax.set_xlabel("月份")
ax.set_ylabel("实发工资")
ax.set_title("27号打工人23年收入")
ax.plot(num_27_2023['月份'],num_27_2023['实发金额'])
plt.show()
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 现代职校董良

评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果